
알고리즘 특강 Week5: 해시 + [Baekjoon] #15829 Hashing
데이터를 다루는 유용한 기법인 ‘해시(hash)’에 대해 정리한다.
그리고 해시함수를 직접 구현해보는 예제(백준 #15829)를 풀어보자.
해시(Hash)
정의
- 데이터를 다루는 기법 중 하나
- 검색/저장에 유용
- key-value 쌍으로 데이터를 저장하는 기법
해시의 구조
key는 각각 unique하며 해시함수를 통하여value로 변환된다.value도 각각 unique하다.- 이러한
key와value를 쌍으로 묶어 저장한다.
파이썬 내장 해시함수
hash()- 미국 NASA에 의해 만들어진 함수로 암호 작성, 데이터 압축에 사용
- 임의의 길이의 값을 입력받아 고정된 길이의 해시값을 출력하는 함수
- 어떤 값을 사용하던지 key에 따라 unique한 value 반환
hash('a') #str
hash(15) #int
hash(12.34) #float
383114906044635003
15
783986623132655628
딕셔너리를 활용한 해시함수 구현
# 딕셔너리 삽입
hash = dict()
hash[1] = 'apple'
hash['banana'] = 3
hash[(4,5)] = [1,2,3] # key로 tuple을 활용할 수도 있다.
hash[10] = dict({1:'a', 2:'b'}) # value로 또다른 딕셔너리를 가질 수도 있다.
- 단, set나 list는 key값으로 쓰일 수 없다. 이들은 해시함수에 의하여 index로 변환될 수 없기 때문이다.
# 딕셔너리 수정
hash[1] = 'melon'
hash['banana'] = 10
# 딕셔너리 추출(dict.pop('key')): value가 추출되며 기존 딕셔너리에선 삭제
hash.pop(1) # melon
hash.pop((4,5)) # [1,2,3]
딕셔너리의 활용(코딩테스트)
딕셔너리 루프
- 반복문을 돌릴 기준을 정해야함
dict.keys(),dict.values()- 딕셔너리의 key(value) 값들을 배열로 반환
dict.items()- tuple형태의 (key, value) 배열 반환
정렬: sorted()
-
Key로 정렬:
sorted(dict.keys, key = lambda x : x - Values로 정렬:
sorted(dict.values(), key = lambda x : x) - 내림차순:
sorted(dict.keys, key = lambda x : -x
예제(Baekjoon #15829 Hashing)
해시함수와 유사한 역할을 하는 함수를 예제를 통해 구현해보자.
문제
APC에 온 것을 환영한다. 만약 여러분이 학교에서 자료구조를 수강했다면 해시 함수에 대해 배웠을 것이다. 해시 함수란 임의의 길이의 입력을 받아서 고정된 길이의 출력을 내보내는 함수로 정의한다. 해시 함수는 무궁무진한 응용 분야를 갖는데, 대표적으로 자료의 저장과 탐색에 쓰인다.
이 문제에서는 여러분이 앞으로 유용하게 쓸 수 있는 해시 함수를 하나 가르쳐주고자 한다. 먼저, 편의상 입력으로 들어오는 문자열에는 영문 소문자(a, b, …, z)로만 구성되어있다고 가정하자. 영어에는 총 26개의 알파벳이 존재하므로 a에는 1, b에는 2, c에는 3, …, z에는 26으로 고유한 번호를 부여할 수 있다. 결과적으로 우리는 하나의 문자열을 수열로 변환할 수 있다. 예를 들어서 문자열 “abba”은 수열 1, 2, 2, 1로 나타낼 수 있다.
해시 값을 계산하기 위해서 우리는 문자열 혹은 수열을 하나의 정수로 치환하려고 한다. 간단하게는 수열의 값을 모두 더할 수도 있다. 해시 함수의 정의에서 유한한 범위의 출력을 가져야 한다고 했으니까 적당히 큰 수 M으로 나눠주자. 짜잔! 해시 함수가 완성되었다. 이를 수식으로 표현하면 아래와 같다.
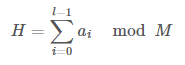
해시 함수의 입력으로 들어올 수 있는 문자열의 종류는 무한하지만 출력 범위는 정해져있다. 다들 비둘기 집의 원리에 대해서는 한 번쯤 들어봤을 것이다. 그 원리에 의하면 서로 다른 문자열이더라도 동일한 해시 값을 가질 수 있다. 이를 해시 충돌이라고 하는데, 좋은 해시 함수는 최대한 충돌이 적게 일어나야 한다. 위에서 정의한 해시 함수는 알파벳의 순서만 바꿔도 충돌이 일어나기 때문에 나쁜 해시 함수이다. 그러니까 조금 더 개선해보자.
어떻게 하면 순서가 달라졌을때 출력값도 달라지게 할 수 있을까? 머리를 굴리면 수열의 각 항마다 고유한 계수를 부여하면 된다는 아이디어를 생각해볼 수 있다. 가장 대표적인 방법은 항의 번호에 해당하는 만큼 특정한 숫자를 거듭제곱해서 곱해준 다음 더하는 것이 있다. 이를 수식으로 표현하면 아래와 같다.
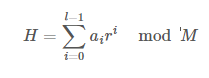
보통 r과 M은 서로소인 숫자로 정하는 것이 일반적이다. 우리가 직접 정하라고 하면 힘들테니까 r의 값은 26보다 큰 소수인 31로 하고 M의 값은 1234567891(놀랍게도 소수이다!!)로 하자.
이제 여러분이 할 일은 위 식을 통해 주어진 문자열의 해시 값을 계산하는 것이다. 그리고 이 함수는 간단해 보여도 자주 쓰이니까 기억해뒀다가 잘 써먹도록 하자.
입력
첫 줄에는 문자열의 길이 L이 들어온다. 둘째 줄에는 영문 소문자로만 이루어진 문자열이 들어온다.
입력으로 주어지는 문자열은 모두 알파벳 소문자로만 구성되어 있다.
출력
문제에서 주어진 해시함수와 입력으로 주어진 문자열을 사용해 계산한 해시 값을 정수로 출력한다.
예제 입력 1 복사
5
abcde
예제 출력 1 복사
4739715
예제 입력 2 복사
3
zzz
예제 출력 2 복사
25818
풀이
l = int(input())
a = input()
res = 0
# 풀이1 시간: 72ms
for i in range(l):
res += (ord(a[i])-96) * (31**i) # ord(c): c의 유니코드 반환, 'a'의 경우 97
answer = res % 1234567891
print(answer)
# 풀이2 시간: 80ms
dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7, 'h':8, 'i':9, 'j':10, 'k':11, 'l':12, 'm':13, 'n':14,
'o':15, 'p':16, 'q':17, 'r':18, 's':19, 't':20, 'u':21, 'v':22, 'w':23, 'x':24, 'y':25, 'z':26}
for i in range(l):
res += dict[a[i]]* (31**i)
answer = res % 1234567891
print(answer)
Leave a comment