
파이썬: Pandas 기본
Pandas
Pandas란?
- 수치형 테이블, 시계열 데이터를 조작/운용하는데 편의성을 제공하는 라이브러리
- 관행적으로 ‘pd’로 호출한다.
import pandas as pd
시리즈(Series)
- DataFrame의 하위 자료형
- NumPy의 ndarray와 달리, 다양한 형식의 데이터를 함께 담을 수 있다.
데이터프레임(DataFrame)
- 행과 열로 이루어진 표 형태의 자료형
- R에서 사용되는 data.frame 구조를 본떠서 만들어짐
- 1개의 열이 시리즈, 이 시리즈가 다수 모여 데이터프레임을 형성한다.
Pandas의 기초 기능
1. 시리즈(Series) 생성
'’리스트’‘로 시리즈 생성
- 리스트 내 데이터 형식이 각각 달라도 시리즈로 생성할 수 있다.
- 실행 결과, 좌측에 나타난 값은 ‘인덱스(줄번호)’로 자동으로 생성된다.
s = pd.Series([1,2,3,'a','b','c']) # 데이터가 형식이 달라도 시리즈로 만들 수 있다.
s
0 1
1 2
2 3
3 a
4 b
5 c
dtype: object # int와 문자열이 섞였으므로 dtype은 object로 표시된다.
# 특징: 자동으로 인덱스(줄번호)를 생성해준다.
'’딕셔너리’‘로 시리즈 생성
- 딕셔너리로 시리즈 생성시엔, ‘key’가 인덱스로 활용된다. (위의 리스트는 자동으로 인덱스 생성)
- 보통은 리스트로 시리즈를 생성하지만, 이 역시 알아두면 좋다.
s = pd.Series({'kor':65, 'eng':78, 'math':89})
s
kor 65
eng 78
math 89
dtype: int6
# key가 인덱스로 자동으로 지정되었음을 확인할 수 있다.
시리즈의 속성(인덱스/값) 반환
- 인덱스 반환 : series.index
- 값 반환: series.values
s = pd.Series([1, 3, 5, 6, 8])
s.index
RangeIndex(start=0, stop=5, step=1)
s.values
array([1, 3, 5, 6, 8], dtype=int64)
2. DataFrame 생성
- 리스트로 생성
- pd.DataFrame(data, [index, columns]) # [] 생략가능, 각각 리스트로 받아옴
# index, column 이름을 지정하지 않으면, 자동으로 숫자가 설정된다.
data = [[1,2,3],[4,5,6],[7,8,9]]
d1 = pd.DataFrame(data)
d1
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9
# 줄이름(index), 열이름(columns) 직접 설정하여 데이터프레임 생성(by list)
index = ['stu1', 'stu2', 'stu3', 'stu4']
cols = ['name', 'num', 'kor', 'eng', 'math']
vals = [['aaa', 1, 54, 56, 67],
['bbb', 2, 98, 76, 56],
['ccc', 3, 78, 89, 54],
['ddd', 4, 96, 35, 86]]
d2 = pd.DataFrame(vals, index=index, columns=cols)
d2
name num kor eng math
stu1 aaa 1 54 56 67
stu2 bbb 2 98 76 56
stu3 ccc 3 78 89 54
stu4 ddd 4 96 35 86
- 딕셔너리로 데이터프레임 생성
- key → 컬럼명으로 활용된다.
# 딕셔너리로 데이터프레임 생성
dic = {
'name': ['aaa', 'bbb', 'ccc', 'ddd'],
'num': [1,2,3,4],
'kor': [76,56,87,76],
'eng': [89,56,45,54],
'math': [98,56,43,87]
}
idx = np.arange(1,5) # 인덱스도 원하는 숫자로 정의
d3 = pd.DataFrame(dic, index=idx)
d3
name num kor eng math
1 aaa 1 76 89 98
2 bbb 2 56 56 56
3 ccc 3 87 45 43
4 ddd 4 76 54 87
데이터프레임의 속성(인덱스/컬럼명/값) 반환
- 인덱스 반환 :dataframe.index
- 컬럼명 반환: dataframe.columns
- 값 반환: dataframe.values
3. 데이터 연산
(1) 시리즈 연산 (+, -, *, /)
a=pd.Series([1,2,3,4])
b=pd.Series([5,6,7,8])
a+b
0 6
1 8
2 10
3 12
dtype: int64
a-b
0 -4
1 -4
2 -4
3 -4
dtype: int64
a*b
0 5
1 12
2 21
3 32
dtype: int64
b/a
0 5.000000
1 3.000000
2 2.333333
3 2.000000
dtype: float64
# 두 시리즈의 크기가 다른 경우, 해당 위치의 계산값은 NaN이 된다.
a=pd.Series([1,2,3])
b=pd.Series([5,6,7,8])
a+b
0 6.0
1 8.0
2 10.0
3 NaN
dtype: float64
(2) 데이터프레임 연산 (+, -, *, /)
- 사이즈가 다른 두 데이터프레임의 연산 결과
d1 = pd.DataFrame({'A':[1,2,3], 'B':[4,5,6], 'C':[7,8,9]})
d1
A B C
0 1 4 7
1 2 5 8
2 3 6 9
d2 = pd.DataFrame({'A':[11,22], 'B':[33,44], 'C':[55,66]})
d2
A B C
0 11 33 55
1 22 44 66
d1+d2
# index가 2인 줄은 연산결과 값이 전부 NaN
A B C
0 12.0 37.0 62.0
1 24.0 49.0 74.0
2 NaN NaN NaN
4. 데이터프레임 통계함수
- 데이터프레임에서 다양한 통계값들을 구해주는 함수를 활용할 수 있다.
| sum() | mean() | std() | var() | min() | max() | cumsum() | cumpord() |
|---|---|---|---|---|---|---|---|
| 합 | 평균 | 표준편차 | 분산 | 최소값 | 최대값 | 누적합 | 누적곱 |
df.sum() # 컬럼별 총합(axis=0이 기본값)
df.mean() # 컬럼별 평균(axis=0이 기본값)
df.mean(axis=1) # 레코드별 평균
- 종합적인 통계를 한번에 보는 방법: df.describe()
df.describe() # 통계를 종합적으로 보게 해줌
| 국어 | 영어 | 수학 | 사회 | 과학 | |
|---|---|---|---|---|---|
| count | 3.0 | 3.0 | 3.000000 | 3.000000 | 3.000000 |
| mean | 65.0 | 56.0 | 84.000000 | 73.000000 | 80.666667 |
| std | 11.0 | 11.0 | 12.165525 | 26.627054 | 21.733231 |
| min | 54.0 | 45.0 | 76.000000 | 45.000000 | 56.000000 |
| 25% | 59.5 | 50.5 | 77.000000 | 60.500000 | 72.500000 |
| 50% | 65.0 | 56.0 | 78.000000 | 76.000000 | 89.000000 |
| 75% | 70.5 | 61.5 | 88.000000 | 87.000000 | 93.000000 |
| max | 76.0 | 67.0 | 98.000000 | 98.000000 | 97.000000 |
5. 데이터프레임의 요소 추출(접근)
- 데이터프레임 요소 추출은 정말로 자주 쓰이는 편
- 따라서, 여러 방법을 숙지하고 있어야 상황에 맞는 적절한 요소 접근이 가능하다.
# 요소접근을 위한 예시 데이터프레임 생성
d = np.arange(100).reshape(10,10)
d = pd.DataFrame(d)
- d는 다음과 같다.
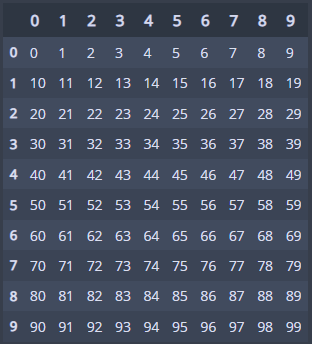
# 다양한 요소 접근 방법
d.head(3) # 맨 위부터 3줄(기본값: 5줄)
d.tail(2) # 맨 뒤부터 2줄(기본값: 5줄)
d[2:5] # 인덱스 범위 지정(2~4번줄)
d.loc[3] # .loc[인덱스명]: 인덱스 이름이 3인 줄을 반환
# 요소접근을 위한 예시 데이터프레임 생성2
s = ['a','b','c','d','e','f','g','h','i','j']
s2 = ['c_a','c_b','c_c','c_d','c_e','c_f','c_g','c_h','c_i','c_j']
d2 = pd.DataFrame(d, index=s, columns=s2)
- d2는 다음과 같다.
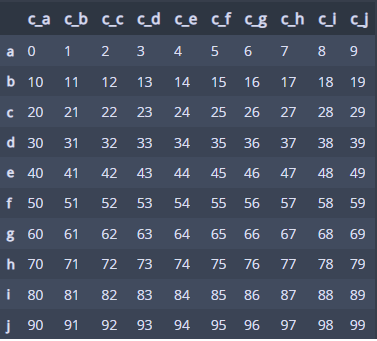
# 다양한 요소 접근 방법
d2.loc['c':'h'] # 인덱스명이 'c'인 레코드부터 'h'인 레코드까지 반환
d2['c_b'] # 컬럼명이 'c_b'인 컬럼 전체
d2['c_b']['c':'f'] # df[col][idx] # 컬럼명이 'c_b'이면서 인덱스가 c~f 사이인 값들
d2.loc['e']['c_e']# .loc[idx][col] <- 순서에 주의
d2.loc['e','c_e'] # .loc[idx,col] 위와 같은 결과
d2['c_e'][1] # df[col][idx_num]인덱스는 위치로도 표현 가능 # 'c_e'컬럼의 인덱스번호가 1인 값
d2['c_e'].loc['f'] # df[col].loc[idx] # 'c_e' 컬럼 중 f 인덱스의 값
d2[d3.columns[1:-1]].loc['f'] # df[col].loc[idx] # 두번째~맨뒤에서 두번째 컬럼의 f 인덱스 값
6. 데이터프레임 통합
- 세로로 통합: df1.append(df2)
- 가로로 통합: df1.join(df2)
- 특정 컬럼 기준으로 가로로 병합: df1.merge(df2)
# 세로로 통합(append)
d1 = pd.DataFrame({'A':[78,67,54,34], 'B':[87,67,65,34]})
d2 = pd.DataFrame({'A':[76,54], 'B':[87,56]})
d3 = d1.append(d2)
print(d1)
print(d2)
print(d3)
A B
0 78 87
1 67 67
2 54 65
3 34 34
A B
0 76 87
1 54 56
A B
0 78 87
1 67 67
2 54 65
3 34 34
0 76 87
1 54 56 <- 인덱스가 원래 인덱스 그대로 들어가는 것을 확인할 수 있다.
d1.append(d2, ignore_index=True) # 원래 인덱스 무시, 새롭게 인덱스 부여
A B
0 78 87
1 67 67
2 54 65
3 34 34
4 76 87
5 54 56
# 가로로 통합(join)
d3 = pd.DataFrame({'C':[65,43,32]})
d1.join(d3)
A B C
0 78 87 65.0
1 67 67 43.0
2 54 65 32.0
3 34 34 NaN <- d3의 인덱스 수가 하나 부족하므로 NaN이 된다.
# d1
판매월 A B
0 1월 54 87
1 2월 65 65
2 3월 76 54
3 4월 78 43
# d2
판매월 C D
0 1월 54 98
1 2월 43 87
2 3월 32 76
3 4월 54 45
# 가로로 병합(merge())
d1.merge(d2) # 병합 기준이 되는 컬럼은 자연스럽게 합쳐짐
판매월 A B C D
0 1월 54 87 54 98
1 2월 65 65 43 87
2 3월 76 54 32 76
3 4월 78 43 54 45
merge함수의 how option(inner, left, right, outer)
- SQL에서의 join과 동일하다.
# d1
판매월 A B
0 1월 54 87
1 2월 65 65
2 3월 76 54
3 4월 78 43
# d2
판매월 C D
0 3월 54 98
1 4월 43 87
2 5월 32 76
3 6월 54 45
# inner join(default)
d1.merge(d2) #how 기본 값: inner # 지정된 열의 공통된 값만
판매월 A B C D
0 3월 76 54 54 98
1 4월 78 43 43 87 -> d1과 d2에서 판매월이 공통되는 부분끼리만 병합
# left join
d1.merge(d2, how='left')
판매월 A B C D
0 1월 54 87 NaN NaN
1 2월 65 65 NaN NaN
2 3월 76 54 54.0 98.0
3 4월 78 43 43.0 87.0 -> 왼쪽(d1)은 전부 다, 오른쪽은 겹치는 부분만 병합, 나머지는 NaN
# right join
d1.merge(d2, how='right')
판매월 A B C D
0 3월 76.0 54.0 54 98
1 4월 78.0 43.0 43 87
2 5월 NaN NaN 32 76
3 6월 NaN NaN 54 45 -> 오른쪽(d2)은 전부 다, 왼쪽은 겹치는 부분만 병합, 나머지는 NaN
# outer join
d1.merge(d2, how='outer')
판매월 A B C D
0 1월 54.0 87.0 NaN NaN
1 2월 65.0 65.0 NaN NaN
2 3월 76.0 54.0 54.0 98.0
3 4월 78.0 43.0 43.0 87.0
4 5월 NaN NaN 32.0 76.0
5 6월 NaN NaN 54.0 45.0
7. 파일 입출력
- 파일 입력: pd.read_csv(파일명, index_col =’컬럼명’)
- 인덱스로 사용할 컬럼을 지정하여 파일 입력(index_col 지정 안하면 자동배정)
- 파일 출력: df.to_csv(만들파일명)
# 파일 입력
pd.read_csv('a.csv', index_col='이름') # '이름' 컬럼을 인덱스로 해서 파일 읽기
국어 영어 수학
이름
aaa 43 54 65
bbb 7 67 87
ccc 54 65 76
# 파일 출력
d1.to_csv('b.csv', encoding='utf-8') # d1 데이터프레임을 b.csv에 저장
Leave a comment